
Can AI produce novel mathematical proofs?

“Can artificial intelligence produce novel mathematical proofs?” — Anonymous
Short answer: My guess is yes, but I think that when we’ll agree that we’ve seen it is a matter of opinion.
Long answer:
AI as a Bad Mathematician
Over the years, I’ve been pretty unimpressed by the mathematical abilities of the AI models I’ve dabbled with, on average — albeit, I’ve almost entirely used free models. Google Gemini, ChatGPT, and DeepSeek have all confidently given me incorrect solutions to simple puzzles, clearly violating stated rules that a solution would need to obey. I’ve also seen plenty of baffling arithmetic errors, like the one below.

A ChatGPT interaction from 2024. (Source: Presh Talwalkar, Mind Your Decisions)
While the models I toyed with could write sonnets and limericks, they seemed to fail at basic logical and arithmetic reasoning. This felt counterintuitive, since if computers excel at one thing over humans, it’s fast and reliable calculations. AI models weren’t designed to calculate in the conventional sense, however — they were designed to jam words, numbers, and other symbols together based on statistical patterns in vast amounts of training data. If they happened to correctly reason through something, it was more or less a happy coincidence based on what they had massaged from that data.
The tech has improved quite a bit since then, but it still often feels like we’ve been given a better version of Borges’ Library of Babel. You can prompt an AI model with a historical event and receive a book on that topic that reads coherently and authoritatively. It’s up to you to decide whether what it spits out is correct or useful, though. And if enough of it seems good, it’s easy to grow complacent and get fooled by the bad.
AI models can now hand over as many attempted proofs of a conjecture as we’ve got time to read. As Terence Tao puts it, AI seems to be ushering in the transition from a world of “proof scarcity” to “proof abundance.” The rub is that most mathematicians understandably don’t want to use the time they would otherwise spend proving theorems to instead grade an abundance of bad AI arguments, hoping that one pans out.
Holding AI to a Standard
One workaround is to give AI models reliable means to check their own work so that they never end up handing us bad work. Since the reason AI models create bad mathematical arguments to begin with is so far characteristic of their design, the assessment rubric needs to be something external, since otherwise we’ll just get sloppy assessments of sloppy proofs.
Right now, the most promising framework is to have AI models convert their proofs into a formal language, like Lean. Since Lean was specifically engineered to evaluate (meticulously-formatted) mathematical arguments in a trustworthy way, the only thing left to vet would be if AI faithfully carried out the translation of the propositions we care about, since Lean would be in charge of reliably assessing the arguments that lead to them.
Below is an example of a traditional proof and the equivalent Lean proof that there are infinitely many primes. The setup in Lean includes definitions of prime numbers and the factorial function and a couple auxiliary theorems.
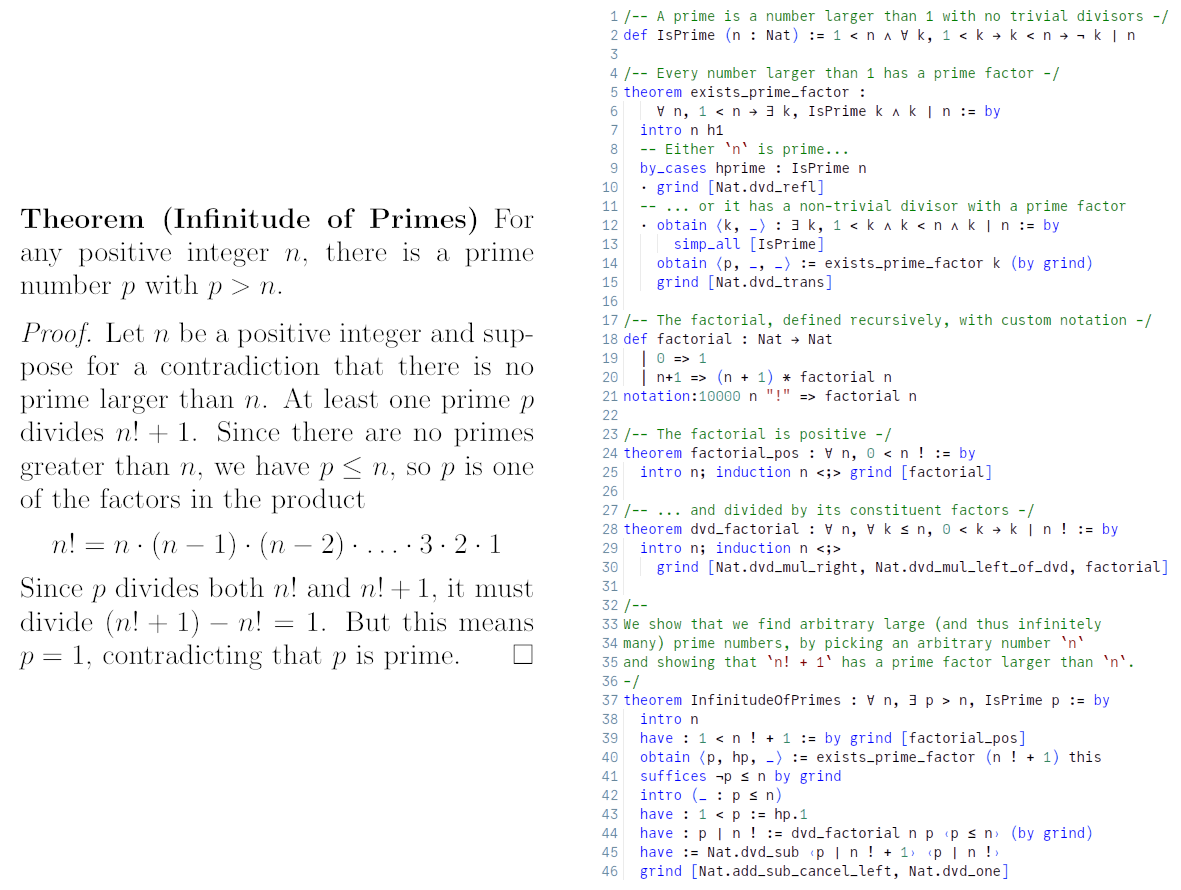
A traditional proof (left) and a Lean proof (right) that there are infinitely many primes. (Lean source: lean-lang.org)
As you might guess, it’s a bit of a slog formalizing a proof in Lean, but this is also the kind of work that AI models have proven good at.
Some AI Successes
A sandbox informally being used to test AI’s ability to construct mathematical arguments is a bank of Erdős problems curated by Thomas Bloom. These problems vary in difficulty and the amount of time mathematicians have spent seriously thinking about them, so it’s hard to tell what solving any given one really means. That said, a number of them have already been solved by AI models or some combination of AI and human effort.
At this point, it seems uncontroversial to say that we have AI proofs of novel mathematical results. There have been many newsworthy results this year (and even this week!) that AI has played some role in resolving. It’s a little trickier to judge whether we’ve seen novel proof ideas. Novelty is a matter of degree and opinion, so I suspect this will be a gray area until we hit some critical threshold of novelty.
This month, a group of nine researchers (including Thomas Bloom) put a paper on the arXiv that detailed an AI-constructed counterexample to Paul Erdős’ unit distance conjecture. Unlike many of the Erdős problems, this one has had a lot of mathematicians sink some serious time into since the original 1946 paper, so it feels like we could say it’s a genuinely hard problem to crack.
The problem is framed in terms of Big O notation, which can make it a little hard to parse, but the gist is this:
If you have n points in the plane, how many pairs can be distance 1 apart?
In particular, how does the maximum possible number of unit distance pairs grow as a function of the number of points if you’re allowed to position the points however you like?
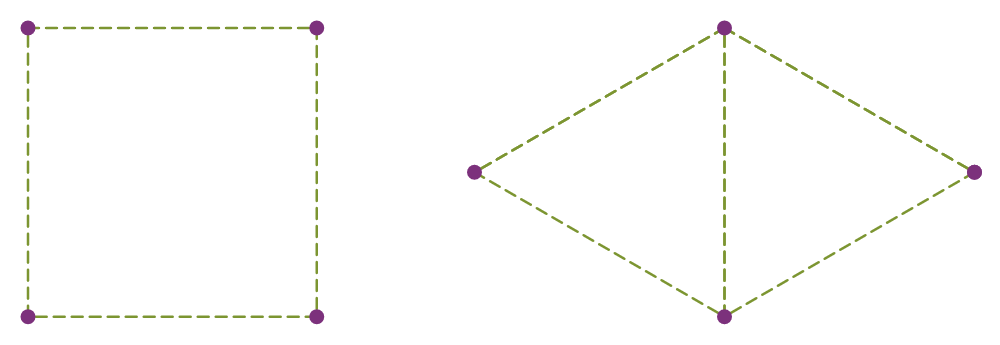
Four points can be arranged so that their are five unit distance pairs.
It turns out that Erdős had conjectured too small a maximum number of unit distance pairs. In one of the easier to digest variants of the conjecture, Erdős’ speculated that as n grows large, the number of unit distance pairs for n points would eventually be smaller than
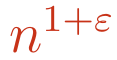
for any choice of ε > 0. However, OpenAI’s model constructed arrangements of points that would not allow for ε to be too small. Will Sawin improved OpenAI’s result, and we now know there are arrangements of n points for infinitely many values of n so that the number of unit distance pairs is at least
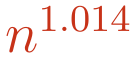
When algebraic number theorists read OpenAI’s construction of its counterexample, they were able to recognize some of the techniques it was using, citing that existing literature in the arXiv preprint. They noted the novel move that OpenAI’s model made was to take a limit of field extensions with degree tending to infinity. (The fields it needed to choose had more conditions on them, but you can roughly think of starting with the rational numbers, then throwing the square root of 2 into the mix to allow for numbers like 3/7 - 5√2, then the cube root of 2, then the golden ratio, and so on, growing your number system incrementally larger.) This sort of limit of field extensions has been used before, but the preprint authors noted that they weren’t aware of it being used in this way. Is that novel enough? You be the judge!
What Novelty Could Look Like
I haven’t dug into many of the other AI proofs, but I’m pretty impressed with OpenAI’s result. It’s high-level mathematics used in the way that mathematicians use it. Paired with formal languages like Lean, it’s also becoming more common for AI models to prove things without much human intervention.
I think the main question left is when we’ll see something that crosses a critical threshold where the output is “deep.” The deep results every mathematician delights in are the ones that connect seemingly disconnected concepts, giving us the ability to reframe problems in one area with the language of another. Those sorts of results tend to give us so much to ponder that they spin out entirely new branches of mathematics.
We think of it as rather mundane now, but the connection between algebra and geometry afforded by graphing in the coordinate plane was revolutionary. Centuries of mathematicians’ attempts to prove Fermat’s last theorem spurred the development of algebraic number theory, which ultimately provided the framework OpenAI used to solve Erdős’ unit distance conjecture. The history of mathematics is full of tricks people used to tackle a problem leading to entire conceptual frameworks that ultimately became more valuable than the solution to the original problem.
I know what that has looked like coming from human mathematicians, because they typically try to make their intuition part of their exposition or, if not, someone else might see a spark and flesh out some intuition for what a trick is “really doing.” It’s that intuition that carries the depth we love to see, since a trick is clever but intuition is powerful. I don’t know what that sort of depth will look like coming from AI, but I suspect it will come eventually. Perhaps AI will get there via an intuition it can describe or be able to rationalize its methods ad hoc, but it might instead simply spit out something provocative and leave us with the task of deciding what the moral is.
If you’re interested in learning more, check out these recent talks by Terence Tao: